Up and Running with JAX - Fully-Connected Network Forward Pass
Implementing the forward pass of a fully-connected neural network using JAX
Machine Learning
Python
Published
April 2, 2025
In a previous post, I introduced JAX with particular emphasis on JIT compilation, vectorizing transformations and automatic differentiation. In this post, we walkthrough an implementation of the forward pass for a fully-connected neural network with the goal of classifying MNIST handwritten digits, incorporating concepts from the first post.
We begin by loading MNIST training and validation sets, convert the PIL images to Numpy arrays, and create image-label batches of size 64:
import warningsimport numpy as npimport pandas as pdimport torchimport torchvisionimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import datasetsfrom torchvision.transforms import ToTensorfrom torchvision.transforms import v2import matplotlib.pyplot as pltnp.set_printoptions(suppress=True, precision=5, linewidth=1000)pd.options.mode.chained_assignment =Nonepd.set_option('display.max_columns', None)pd.set_option('display.width', None)pd.set_option("display.precision", 5)warnings.filterwarnings("ignore")# Batch size.bs =64train_data = datasets.MNIST( root="data", train=True, download=True, transform=v2.Compose([ToTensor()]))valid_data = datasets.MNIST( root="data", train=False, download=True, transform=v2.Compose([ToTensor()]))# Convert PIL images to NumPy arrays.train_data_arr = train_data.data.numpy() /255.0# Normalize pixel values to [0, 1]valid_data_arr = valid_data.data.numpy() /255.0# Normalize pixel values to [0, 1] train_data_arr = train_data_arr.reshape(-1, 28*28) # Flatten images to 1D arraysvalid_data_arr = valid_data_arr.reshape(-1, 28*28) # Flatten images to 1D arraystrain_labels = train_data.targets.numpy()valid_labels = valid_data.targets.numpy()# Create training and validation batches of 64.train_batches = [ (train_data_arr[(bs * ii):(bs * (ii +1))], train_labels[(bs * ii):(bs * (ii +1))]) for ii inrange(len(train_data_arr) // bs)]valid_batches = [ (valid_data_arr[(bs * ii):(bs * (ii +1))], valid_labels[(bs * ii):(bs * (ii +1))]) for ii inrange(len(valid_data_arr) // bs)]print(f"train_data_arr.shape: {train_data_arr.shape}")print(f"valid_data_arr.shape: {valid_data_arr.shape}")print(f"train_labels.shape : {train_labels.shape}")print(f"valid_labels.shape : {valid_labels.shape}")print(f"len(train_batches) : {len(train_batches)}")print(f"len(valid_batches) : {len(valid_batches)}")
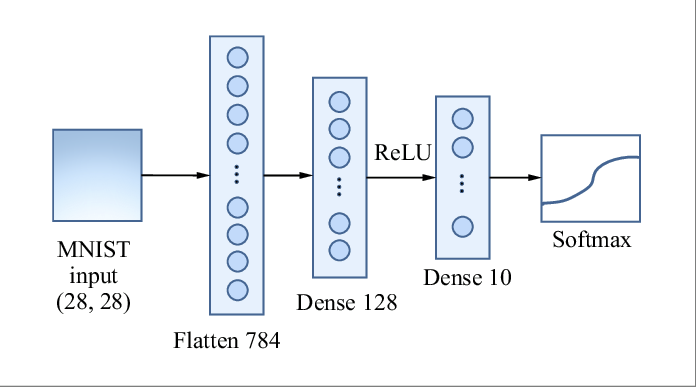
Our goal is to create a model that accepts a batch of 64 images, and returns a class prediction for each image in the batch. Our architecture is presented in the image below:
The pre-activations for layer \(l\) are computed as \(Z^{(l)} = A^{(l-1)} W^{(l)} + b^{(l)}\), where:
\(Z^{(l)}\) = layer \(l\) pre-activations (value prior to applying non-linearity like ReLU).
\(A^{(l-1)}\) = layer \(l-1\) activations, with \(A^{(0)}\) representing the original input.
\(W^{(l)}\) = The weight matrix for layer \(l\).
\(b^{(l)}\) = bias vector for layer \(l\).
For the network shown above assuming a batch size of 64:
\(Z^{(0)} = A^{(0)}\): Input matrix with dimension 64x784.
\(W^{(1)}\): Weight matrix with dimension 784x128.
\(b^{(1)}\) Bias vector of length 128.
\(Z^{(1)} = A^{(0)} W^{(1)} + b^{(1)}\): Matrix of pre-activations with dimension 64x128.
\(A^{(1)}\): Non-linearity applied to \(Z^{(1)}\). Activation matrix with dimension 64x128.
\(W^{(2)}\): Weight matrix with dimension 128x10.
\(b^{(2)}\): Bias vector of length 10.
\(Z^{(2)} = A^{(1)} W^{(2)} + b^{(2)}\): Matrix of pre-activations with dimension 64x10.
\(A^{(2)}\): Non-linearity applied to \(Z^{(2)}\). Activation matrix with dimension 64x10.
The forward pass feeds an image of size 28x28 into the network, which produces a probability distribution over all classes. The class with the highest probability is our class prediction, which for MNIST will be one of 10 digits 0-9. Specifically:
Each 28x28 image is flattened to have shape 1x784. The input layer has the same size as the flattened image (784,).
The hidden layer consists of 128 neurons. The matrix of weights projecting from the input layer to the first hidden layer has dimension 784x128, plus a bias vector of length 128.
The output layer consists of 10 neurons, which is the same the number of classes in the dataset. The matrix of weights projecting from the hidden layer to the output layer has dimension 128x10, along with a bias vector of length 10.
Applying softmax to the output layer results in a probability distribution over classes.
Weight initialization is handled automatically in PyTorch, but when working in JAX, The first step is to initialize the network weights. We can create a helper function to assist with randomly assigning values to the weight matrices and bias vectors.
In JAX, random number generation is handled a bit differently than in Numpy to ensure functional purity. JAX uses explicit PRNG keys to generate random numbers instead of relying on global state. A “key” is a special array that acts as a seed, and every time you use it, JAX produces the same random numbers for the same key.
Since JAX enforces immutability, you can’t reuse a key for multiple random calls without getting the same result. Instead, you split a key using jax.random.split, which deterministically generates new, unique keys from the original one. Each split key is independent, allowing for the generation of different random numbers while maintaining reproducibility. In the next cell, we initialize weights using small random normal values:
from jax import randomdef initialize_weights(sizes, key, scale=.02):""" "Initialize weights and biases for each layer for simple fully-connected network. Parameters ---------- sizes : list of int List of integers representing the number of neurons in each layer. key : jax.random.PRNGKey Random key for JAX. Returns ------- List of iniitialized weights and biases for each layer. """ keys = random.split(key, len(sizes) -1) params = []for m, n, k inzip(sizes[:-1], sizes[1:], keys): w_key, b_key = random.split(k) w = scale * random.normal(w_key, (m, n)) b = scale * random.normal(b_key, (n,)) params.append((w, b))return params# Initialize weights and biases for each layer.sizes = [784, 128, 10]params = initialize_weights(sizes, key=random.PRNGKey(516), scale=.02) # Print shape of each layer's weights and biases.print(f"W1 shape: {params[0][0].shape}")print(f"b1 shape: {params[0][1].shape}")print(f"W2 shape: {params[1][0].shape}") print(f"b2 shape: {params[1][1].shape}")
In PyTorch, models inherit from nn.Module and must implement a forward method that defines the network’s computation flow. The forward method orchestrates how input tensors transform through pre-specified operations to produce outputs.
For our JAX implementation we’ll create a similar function, but the weights must be explicitly passed as parameters rather than stored as internal state. Unlike PyTorch’s object-oriented approach where weights are hidden properties of the model instance, JAX follows a functional paradigm that requires all state to be passed explicitly between function calls, eliminating hidden state.
In our forward function, we incorporate ReLU activation between layers to introduce non-linearity:
import jax.numpy as jnpfrom jax.nn import reludef forward(params, X):""" Forward pass for simple fully-connected network. Parameters ---------- params : list of tuples List of tuples containing weights and biases for each layer. X : jax.numpy.ndarray Input data. Returns ------- jax.numpy.ndarray """ a = Xfor W, b in params[:-1]: z = jnp.dot(a, W) + b a = relu(z) W, b = params[-1]return jnp.dot(a, W) + b
We can pass a single flattened image array into forward, and it should return a 1x10 vector of activations. The output will not be a probability distribution since softmax hasn’t been applied, but we can still test it to ensure that the shape of the output is consistent with our expectations:
# Get first image from first training batch.X, y = train_batches[0]# Convert to JAX array.X0 = jnp.asarray(X[0].flatten())# Pass X0 into forward.ypred = forward(params, X0)print(f"ypred.shape: {ypred.shape}")print(f"ypred: {ypred}")
As implmented, forward is only capable of processing a single flattened image at a time. However, we can use vmap, introduced in the first post, to process a batch of images at a time without any modification to forward. vmap enables batch processing while taking advantage of JAX’s optimized execution. Instead of using loops, it efficiently maps a function over an array along a pre-specified axis:
from jax import vmapbatch_forward = vmap(forward, in_axes=(None, 0))
in_axes controls which input array axes to vectorize over, and its length must equal the number of positional arguments associated with the original function. In our case, the first argument to forward is params, which stays the same within the context of the forward pass. The second argument corresponds to our input image, and the ‘0’ indicates that vectorization should be applied along the 0th axis (which is batch dimension).
We can pass a batch of size 64 x 784 into batch_forward, and return an output of size 64x10:
# Get first batch of flattened training images.X, y = train_batches[0]ypreds = batch_forward(params, X)print(f"ypreds.shape: {ypreds.shape}")print(f"ypreds:\n{ypreds}")
At this point, the outputs are meaningless and are pretty close to uniformly distributed over classes. This is because we haven’t yet calculated the gradient of the loss function with respect to each weight, which allows the network to adjust its weights and biases to minimize prediction errors. In the next post, we’ll implement backpropagation entirely in JAX and walkthrough how to construct the training and validation loops.