Introduction to Markov Chain Monte Carlo - The Metropolis-Hastings Algorithm
Introduction to markov chain monte carlo - The Metropolis-Hastings algorithm
Statistical Modeling
Python
Published
September 21, 2024
Markov Chain Monte Carlo (MCMC) is a class of algorithms used to sample from probability distributions when direct sampling is difficult or inefficient. It leverages Markov chains to explore the target distribution and Monte Carlo methods to perform repeated random sampling. MCMC algorithms are widely used in the insurance industry, particularly in areas involving risk assessment, pricing, reserving, and capital modeling. Markov Chain Monte Carlo is an alternative to rejection sampling, which can be inefficient when dealing with high-dimensional probability distributions. MCMC is considered a Bayesian approach to statistical inference since it incorporates both prior knowledge and observed data into the estimation of the posterior distribution.
The Metropolis-Hastings algorithm is a method used to generate a sequence of samples from a probability distribution for which direct sampling might be difficult. It is a particiular variant of MCMC, which approximates a desired distribution by creating a chain of values that resemble samples drawn from that distribution. The algorithm generates a sequence of samples by proposing new candidates and deciding whether to accept or reject them based on a ratio of probabilities from the target distribution.
Before getting into the details of Metropolis-Hastings, a few key definitions:
Likelihood: The apriori assumption specifying the distribution from which the data are assumed to originate. For example, if we assume losses follow an exponential distribution within unknown parameter \(\theta\), this is equivalent to specifying an exponential likelihood. Symbolically, the likelihood is represented as \(f(x|\theta)\).
Prior: Sticking with the exponential likelihood example, once we’ve proposed the likelihood, we need to specify a distribution for each parameter of the likelihood. In the case of the exponential there is only a single parameter, \(\theta\). Typically when selecting prior distributions, it should have the same domain as the parameter itself. When parameterizing the exponential distribution, we know that \(0 < \theta < \infty\), so the prior distribution should be valid on \((0, \infty)\). Valid distributions for \(\theta\) are gamma, lognormal, pareto, weibull, etc. Invalid distributions would be any discrete distribution or the normal distribution. Symbolically, the prior is represented as \(f(\theta)\).
Posterior: This is the expression which encapsulates the power, simplicity and flexibility of the Bayesian approach and is given by:
The posterior is represented as \(f(\theta|x)\), so the above expression becomes:
\[
f(\theta|x) \propto f(x|\theta) f(\theta).
\]
We can update the proportionality to direct equality by the inclusion of a normalizing constant, which ensures the expression on the RHS integrates to 1:
Suppose we have a collection of \(\{\theta^{(1)}, \dots \theta^{(s)}\}\), to which we would like to add a new value \(\theta^{(s+1)}\). We generate a sample from our transition kernel \(\theta^{*}\) which is nearby \(\theta^{(s)}\).
If \(f(\theta^{*}|y) > f(\theta^{(s)}|y)\), then we should include \(\theta^{*}\) with probability 1.
If \(f(\theta^{*}|y) < f(\theta^{(s)}|y)\), we will include \(\theta^{*}\) with probability determined by the acceptance ratio.
If \(\alpha\) >= 1: We add \(\theta^{*}\) to our collection of samples, since it has a higher likelihood than \(\theta^{(s)}\). Set \(\theta^{(s + 1)} = \theta^{*}\).
If \(\alpha\) < 1: Set \(\theta^{(s + 1)} = \theta^{*}\) with probability \(\alpha\).
Notice that the acceptance ratio is calculated without needing to compute the normalizing constant \(f(y)\), which can be difficult to do, especially in high-dimensional settings. This is the power of Metropolis-Hastings and MCMC in general: It provides a way to approximate the posterior distribution by generating samples from it without direct calculation of the normalizing constant.
Metropolis-Hastings accept-reject logic can be summarized in three steps:
Generate sample from proposal distribution / transition kernel \(\theta^{*} \sim J(\theta|\theta^{(s)})\).
Compute acceptance ratio \(\alpha = \frac{f(y|\theta^{*}) f(\theta^{*})}{f(y|\theta^{(s)}) f(\theta^{(s)})}\).
Sample \(u \sim \mathrm{uniform}(0, 1)\).
If \(\alpha \geq u\), set \(\theta^{(s + 1)} = \theta^{*}\).
If \(\alpha < u\), set \(\theta^{(s + 1)} = \theta^{(s)}\).
Conjugate Priors
Conjugate priors are a class of prior distributions in Bayesian statistics that result in a posterior distribution that has the same functional form as the prior when combined with a particular likelihood function. This makes the posterior distribution easier to compute and analyze, as it remains within the same family of distributions as the prior. For example, if we select an exponential likelihood with a gamma prior, the posterior distribution is also gamma, with a specified parameterization.
Further, many of these conjugate priors have analytical expressions for the posterior predictive distribution, which represents the modeled target output of our analysis. We can use conjugate prior relationships as a means to validate the output of our MCMC sampler.
Example: Conjugate Normal-Normal Model with Known Variance
Let’s start with a simple example where we assume a model with normal likelihood and prior (adapted from Chapter 10 of A First Course in Bayesian Statistical Methods by Peter Hoff). Assume:
The posterior distribution parameter estimates have been updated in the direction of the data. Next imagine a scenario in which closed form expressions for posterior parameters did not exist, and it was necessary to use Metropolis-Hastings to approximate the posterior. The acceptance ratio comparing \(\theta^{*}\) to \(\theta^{(s)}\) is:
An implementation of Metropolis-Hastings to recover the posterior mean is provided below.
"""Implementation of Metropolis-Hastings algorithm for normal likelihood and normal prior with known variance.Goal is to recover the posterior distribution of the unknown parameter mu. """import numpy as npfrom scipy.stats import normrng = np.random.default_rng(516)y = [9.37, 10.18, 9.16, 11.60, 10.33]nbr_samples =10000# Number of samples to generate.s =1# Standard deviation of likelihood.s0 =10**.5# Prior standard deviation.mu0 =5# Prior mean.s_prop =2# Standard deviation of proposal distribution / transition kernel.# Array to hold posterior samples, initialized with prior mean.samples = np.zeros(nbr_samples)# Initialize prior density.prior = norm(loc=mu0, scale=s0)# Track the number of accepted samples. accepted =0for ii inrange(1, nbr_samples):# Get most recently accepted sample. theta = samples[ii -1]# Generate sample from proposal distribution. theta_star = rng.normal(loc=theta, scale=s_prop)# Compute numerator and denominator of acceptance ratio. numer = np.prod(norm(loc=theta_star, scale=s).pdf(y)) * prior.pdf(theta_star) denom = np.prod(norm(loc=theta, scale=s).pdf(y)) * prior.pdf(theta) ar = numer / denom# Generate random uniform sample. u = rng.uniform(low=0, high=1)# Check whether theta_star should be added to samples by comparing ar with u.if ar >= u: theta = theta_star accepted+=1# Update samples array. samples[ii] = thetaif ii %1000==0:print(f"{ii}: theta_star: {theta_star:.5f}, ar: {ar:.5f}, curr_rate: {accepted / ii:.5f}")acc_rate = accepted / nbr_samplesprint(f"\nAcceptance rate : {acc_rate:.3f}.")print(f"Posterior mean (mh) : {samples.mean():.5f}.")print(f"Posterior mean (cp) : {mu_posterior:.5f}.")
Generally the acceptance rate should fall between 20%-40%, so our result seems reasonable, if not a little on the low side.
In the Metropolis-Hastings update step, we compute the product of many potentially small numbers to determine the acceptance ratio, which can be numerically unstable. We can instead compute the log of the RHS of the acceptance ratio, which will result in more stability especially as the number of data points increases. The posterior estimates will be no different, but we reduce the chance of numerical underflow by replacing the product with a sum. The update step using the log basis is given below:
"""Implementation of Metropolis-Hastings algorithm for Normal likelihood and Normal prior with known variance.Goal is to recover the posterior distribution of the unknown parameter mu. """import numpy as npfrom scipy.stats import normrng = np.random.default_rng(516)y = [9.37, 10.18, 9.16, 11.60, 10.33]nbr_samples =10000# Number of samples to generate.s =1# Standard deviation of likelihood.s0 =10**.5# Prior standard deviation.mu0 =5# Prior mean.s_prop =2# Standard deviation of proposal distribution / transition kernel.# Array to hold posterior samples, initialized with prior mean.samples = np.zeros(nbr_samples)# Initialize prior density.prior = norm(loc=mu0, scale=s0)# Track the number of accepted samples. accepted =0for ii inrange(1, nbr_samples):# Get most recently accepted sample. theta = samples[ii -1]# Generate sample from proposal distribution. theta_star = rng.normal(loc=theta, scale=s_prop)# Compute numerator and denominator of acceptance ratio using log basis. ar = (np.sum(norm(loc=theta_star, scale=s).logpdf(y)) + prior.logpdf(theta_star)) -\ (np.sum(norm(loc=theta, scale=s).logpdf(y)) + prior.logpdf(theta))# Generate random uniform sample. u = rng.uniform(low=0, high=1)# Check whether theta_star should be added to samples by comparing a with u.if ar >= np.log(u): theta = theta_star accepted+=1# Update samples array. samples[ii] = thetaif ii %1000==0:print(f"{ii}: theta_star: {theta_star:.5f}, ar: {ar:.5f}, curr_rate: {accepted / ii:.5f}")acc_rate = accepted / nbr_samplesprint(f"\nAcceptance rate : {acc_rate:.3f}.")print(f"Posterior mean (mh) : {samples.mean():.5f}.")print(f"Posterior mean (cp) : {mu_posterior:.5f}.")
As expected, this aligns with the original non-log basis results.
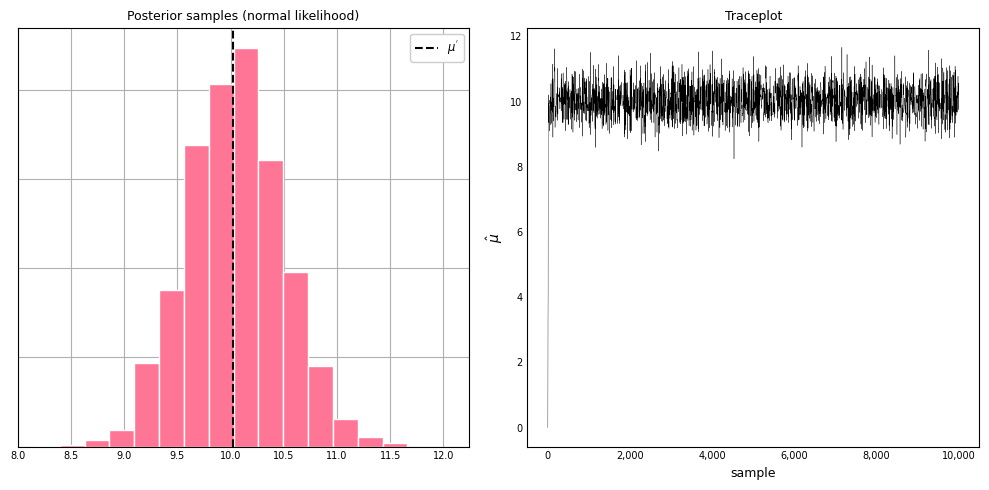
We can visualize the distribution of posterior samples as well as the traceplot. Traceplots are graphical tools used to diagnose the convergence and mixing of MCMC simulations. They help assess whether the algorithm has properly explored the target distribution and whether the samples are representative of the posterior distribution.
Notice in the traceplot that even though we started far from the estimated posterior mean, it made little difference, as the algorithm was able to quickly zero in on the region of higher likelihood. You want to see that the samples have stabilized around a certain value after an initial “burn-in” period. If the trace shows significant fluctuations without settling, it may indicate that the chain has not yet converged. This is not the case with our samples.
Severity Modeling
MCMC approaches can be leveraged to estimate severity or size-of-loss curves for a given line of business based on past claim history. Severity estimates are used in multiple actuarial contexts, especially reserving and capital modeling. Imagine we have loss data we believe originates from an exponential distribution with unknown rate parameter:
266, 934, 138
We again assume a conjugate relationship between prior and posterior distributions:
Likelihood: Losses are exponentially distributed with unknown rate \(\lambda\).
Prior: Gamma with \(\alpha_{0}\), \(\beta_{0}\).
Posterior: Gamma with \(\alpha^{'} = \alpha_{0} + n\) and \(\beta^{'} = \beta_{0} + \sum_{i=1}^{n} x_{i}\).
Posterior predictive: Lomax (shifted Pareto with support beginning at zero) with \(\alpha^{'}, \beta^{'}\). The expected value of the posterior predictive distribution is \(\frac{\beta^{'}}{\alpha^{'} - 1}\).
We judgmentally set \(\alpha_{0} = 2\) and \(\beta_{0} = 1,000\). Prior and posterior predictive means are computed in the next cell.
a0 : 2
b0 : 1000
a_posterior : 5.
b_posterior : 2338.
Empirical mean : 446.0
Prior mean : 2000
Post. pred. mean: 584.50
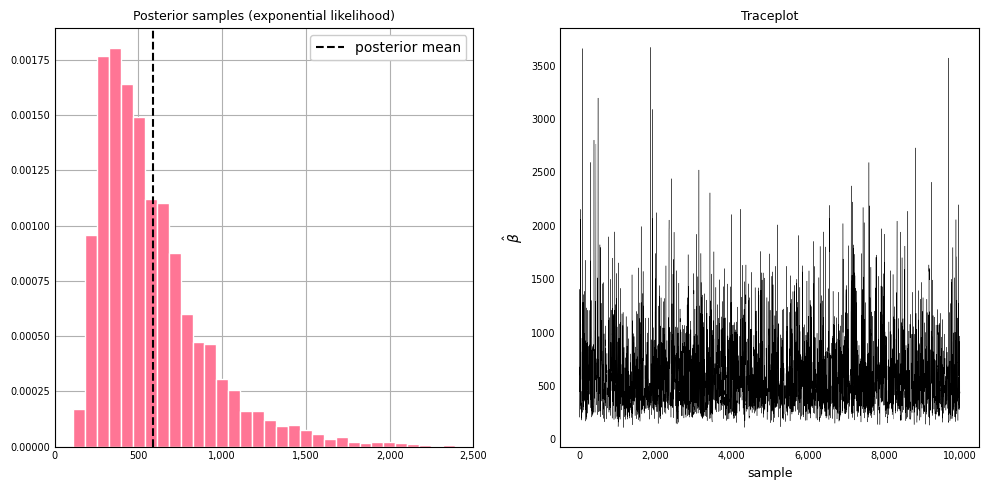
Using Metropolis-Hastings, the mean of generated samples should match the posterior predictive mean obtained from the analytical expression (584.50 above). Adapting the sampling code from the previous model, an exponential distribution is used to generate proposals, since the exponential scale parameter must be strictly greater than 0. We have the following:
"""Implementation of Metropolis-Hastings algorithm for exponential likelihoodwith gamma prior.Goal is to recover the posterior distribution of the unknown parameter lambda. """import numpy as npfrom scipy.stats import expon, norm, gamma, lomaxrng = np.random.default_rng(516)nbr_samples =10000y = [266, 934, 138]a0 =2b0 =1000# Array to hold posterior samples, initialized with prior mean.samples = np.zeros(nbr_samples)samples[0] = np.mean(y)# Initialize prior density.prior = gamma(a=a0, loc=0, scale=b0)# Track the number of accepted samples. accepted =0for ii inrange(1, nbr_samples):# Get most recently accepted sample. theta = samples[ii -1]# Generate sample from proposal distribution. theta_star = rng.exponential(scale=theta)# Compute numerator and denominator of acceptance ratio. numer = np.prod(expon(scale=theta_star).pdf(y)) * prior.pdf(theta_star) denom = np.prod(expon(scale=theta).pdf(y)) * prior.pdf(theta) ar = numer / denom# Generate random uniform sample. u = rng.uniform(low=0, high=1)# Check whether theta_star should be added to samples by comparing ar with u.if ar >= u: theta = theta_star accepted+=1# Update samples array. samples[ii] = thetaif ii %1000==0:print(f"{ii}: theta_star: {theta_star:.5f}, ar: {ar:.5f}, curr_rate: {accepted / ii:.5f}")acc_rate = accepted / nbr_samplesprint(f"\nAcceptance rate : {acc_rate:.3f}.")print(f"Posterior sample mean: {samples.mean():.3f}.")
The distribution of posterior samples resembles a gamma distribution, which we expect.
Next, to generate posterior predictive samples, we randomly sample from an exponential distribution parameterized using each scale parameter. This is accomplished in the next cell:
"""Generate posterior predictive samples, one random draw per posterior scale sample."""post_pred_samples = rng.exponential(scale=samples)print(f"Posterior predictive mean (cp): {post_pred_mean:.5f}")print(f"Posterior predictive mean (mh): {post_pred_samples.mean():.5f}")
Posterior predictive mean (cp): 584.50000
Posterior predictive mean (mh): 585.71307
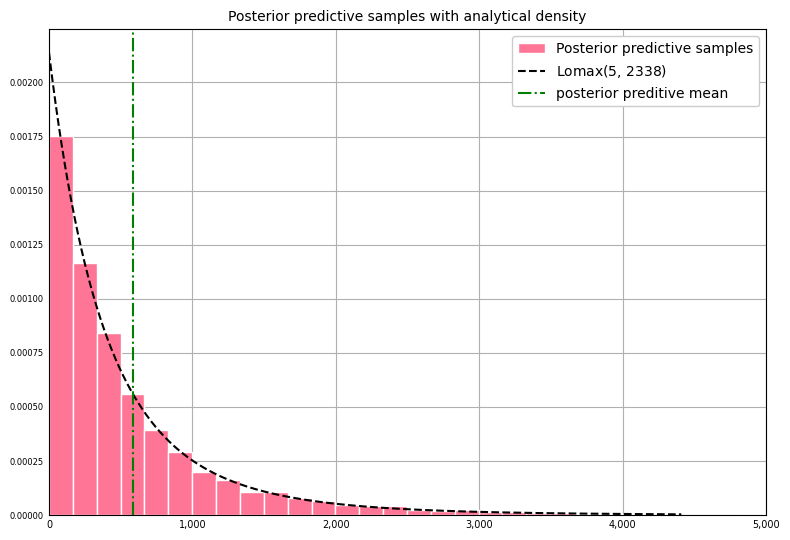
We can overlay the posterior predictive distribution with the histogram of posterior predictive samples and assess how well they match:
The plot shows the two distributions align well. Finally, we can compare quantiles of our posterior predictive samples with the analytical density to see how well they agree in the extreme left and right tails:
cp represents analytical quantiles from the conjugate prior posterior predictive distribution.
mh represents quantiles from the Metropolis-Hastings generated posterior predictive samples.
error represents the percent deviation from analytical quantiles.
Even at q=0.999, cp and mh differ by less than 1.50%.
Unfortunately, most distributional relationships used in practice are not conjugate. But by leveraging conjugate relationships we were able to demonstrate that when the same likelihood, prior and loss data are used, Metropolis-Hastings will yield distributional estimates of the posterior predictive distribution very to close to the analytical distribution.
While implementing your own MCMC sampler is a great way to gain a better understanding of the inner workings of Markov Chain Monte Carlo, in practice it is almost always preferrable to an optimized MCMC library such as PyStan or PyMC3. These will be explored in a future post.