Up and Running with JAX - Backpropagation and Training Neural Networks
Implementing the loss function, backward pass and training loop in JAX
Machine Learning
Python
Published
April 14, 2025
In the third and final installment of the Up and Running with JAX series, we demonstrate the remaining steps required to train and evaluate a simple neural network, specifically the implementation of the loss function, backward pass and training loop. As in Part 2, the focus will be on predicting class labels for the MNIST dataset, which consists of 28x28 pixel images of handwritten digits (0-9). The training loop consists of the following steps:
Load a batch of training data.
Obtain model predictions for current batch of images.
Calculate the loss for current batch predictions vs. targets.
Calculate backward gradients over the weights and biases.
Update the weights and biases using the gradient information.
Calculate the loss on a set of images not used for training.
We begin by loading the dataset and functions implemented in Part 2 that facilitate weight initialization and the network forward pass:
import warningsimport numpy as npimport pandas as pdimport torchimport torchvisionimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import datasetsfrom torchvision.transforms import ToTensorfrom torchvision.transforms import v2import matplotlib.pyplot as pltnp.set_printoptions(suppress=True, precision=5, linewidth=1000)pd.options.mode.chained_assignment =Nonepd.set_option('display.max_columns', None)pd.set_option('display.width', None)pd.set_option("display.precision", 5)warnings.filterwarnings("ignore")# Batch size.bs =64train_data = datasets.MNIST( root="data", train=True, download=True, transform=v2.Compose([ToTensor()]))valid_data = datasets.MNIST( root="data", train=False, download=True, transform=v2.Compose([ToTensor()]))# Convert PIL images to NumPy arrays.train_data_arr = train_data.data.numpy() /255.0# Normalize pixel values to [0, 1]valid_data_arr = valid_data.data.numpy() /255.0# Normalize pixel values to [0, 1] train_data_arr = train_data_arr.reshape(-1, 28*28) # Flatten images to 1D arraysvalid_data_arr = valid_data_arr.reshape(-1, 28*28) # Flatten images to 1D arraystrain_labels = train_data.targets.numpy()valid_labels = valid_data.targets.numpy()# Create training and validation batches of 64.train_batches = [ (train_data_arr[(bs * ii):(bs * (ii +1))], train_labels[(bs * ii):(bs * (ii +1))]) for ii inrange(len(train_data_arr) // bs)]valid_batches = [ (valid_data_arr[(bs * ii):(bs * (ii +1))], valid_labels[(bs * ii):(bs * (ii +1))]) for ii inrange(len(valid_data_arr) // bs)]print(f"train_data_arr.shape: {train_data_arr.shape}")print(f"valid_data_arr.shape: {valid_data_arr.shape}")print(f"train_labels.shape : {train_labels.shape}")print(f"valid_labels.shape : {valid_labels.shape}")print(f"len(train_batches) : {len(train_batches)}")print(f"len(valid_batches) : {len(valid_batches)}")
"""Functions introduced in Part 2. Refer to https://www.jtrive.com/posts/intro-to-jax-part-2/intro-to-jax-part-2.htmlfor more information. """from jax import random, vmapimport jax.numpy as jnpfrom jax.nn import reludef initialize_weights(sizes, key, scale=.02):""" "Initialize weights and biases for each layer for simple fully-connected network. Parameters ---------- sizes : list of int List of integers representing the number of neurons in each layer. key : jax.random.PRNGKey Random key for JAX. Returns ------- List of initialized weights and biases for each layer. """ keys = random.split(key, len(sizes) -1) params = []for m, n, k inzip(sizes[:-1], sizes[1:], keys): w_key, b_key = random.split(k) w = scale * random.normal(w_key, (m, n)) b = scale * random.normal(b_key, (n,)) params.append((w, b))return paramsdef forward(params, X):""" Forward pass for simple fully-connected network. Parameters ---------- params : list of tuples List of tuples containing weights and biases for each layer. X : jax.numpy.ndarray Input data. Returns ------- jax.numpy.ndarray """ a = Xfor W, b in params[:-1]: z = jnp.dot(a, W) + b a = relu(z) W, b = params[-1]return jnp.dot(a, W) + b# Auto-vectorization of forward pass.batch_forward = vmap(forward, in_axes=(None, 0))
Cross-Entropy Loss and Softmax
Categorical cross-entropy loss is the most commonly used loss function for multi-class classification with mutually-exclusive classes. A lower cross-entropy loss means the predicted probabilities are closer to the true labels. A key characteristic of cross entropy loss is that it rewards/penalizes the probabilities of correct classes only: The value is independent of how the remaining probability is split between the incorrect classes.
For a single sample with ( C ) classes, the cross-entropy loss is give by
\[
L = - \frac{1}{n}\sum_{i=1}^{C} y_i \times \log(\hat{y_i}),
\]
where: - \(n\) is the batch size. - \(y_i\) is the true label (1 for the correct class, 0 otherwise). - \(\hat{y_i}\) is the predicted probability for class \(i\) (from softmax). - The \(\log\) ensures the loss is large when the predicted probability is low for the correct class.
If we had a single vector of actual labels representing the index of the correct class (i.e., yact from above), simply compute the negative log of the probability at this index to get the cross entropy loss for that sample (since cross-entropy doesn’t consider incorrect classes).
We forego one-hot encoding our targets, so our loss function accepts a batch of final layer activations (logits) and targets (labels) represented as a single integer between 0 and 9 per sample. Using a batch size of 64, logits has shape (64, 10), and labels (64,):
from jax.nn import log_softmaxdef cross_entropy_loss(params, X, y):""" Compute the loss for the given logits and labels. Parameters ---------- params : list of tuples List of tuples containing weights and biases for each layer. logits : Batch of final layer activations. labels : Batch of true labels, a single integer per sample. Returns ------- Computed loss. """# Compute logits for the batch. logits = forward(params, X)# Convert logits to log probabilities. log_probs = log_softmax(logits)return-log_probs[jnp.arange(len(y)), y].mean()
The softmax function converts a vector logits into a probability distribution over classes. Logits refer to the raw, unnormalized output values produced by the last layer of a neural network before applying an activation function. It is commonly used in classification tasks. In some deep learning frameworks, cross-entropy loss is combined with softmax within a single function (see for example, CrossEntropyLoss in PyTorch). For a vector \(z\) of length \(n\), softmax is defined as:
The denominator ensures all probabilities sum to 1.
If any of the \(z_i\) is large, \(e^{z_i}\) can become extremely large, potentially causing overflow errors in computation. For example:
import numpy as npz = np.array([1000, 2000, 3000]) # Large valuessoftmax = np.exp(z) / np.sum(np.exp(z)) # OverflowError
Since \(e^{3000}\) is astronomically large, Python will struggle to handle it. The solution is to subtract the max value of each sample instead of using \(z\) directly:
This shifts all values down without affecting the final probabilities (since shifting inside the exponent maintains relative differences).
Backward Pass
In order to obtain the gradients of the loss function w.r.t. the model parameters, JAX’s grad function can be used. grad computes the gradient of a scalar-valued function with respect to its inputs. It performs automatic differentiation by tracing the computation and building a backward pass to compute derivatives. grad accepts a Python function and returns a new function that computes the gradient of the original function. The returned function takes the same inputs as the original and returns the derivative w.r.t. the argument specified (the first argument by default).
Note that grad only returns the gradients of the loss function with respect to the parameters, and not the actual loss value. This is important information to have during training. We can instead use value_and_grad, which returns the actual loss value along with the gradients as a tuple. In the next cell, update implements the gradient update. I’ve included an accuracy function, which is used to evaluate model performance after each epoch:
from jax import value_and_graddef update(params, X, y, lr=.01):""" Update weights and biases using gradient descent. Parameters ---------- params : list of tuples List of tuples containing weights and biases for each layer. X : jax.numpy.ndarray Input data. y : jax.numpy.ndarray True labels. lr : float Learning rate. Returns ------- tuple Updated weights and biases. """# Compute loss and gradients. loss, grads = value_and_grad(cross_entropy_loss)(params, X, y)# Unpack parameters and gradients. (W1, b1), (W2, b2) = params (dW1, db1), (dW2, db2) = grads# Update weights and biases. W1_new = W1 - lr * dW1 b1_new = b1 - lr * db1 W2_new = W2 - lr * dW2 b2_new = b2 - lr * db2return [(W1_new, b1_new), (W2_new, b2_new)], lossdef accuracy(logits, labels):""" Compute accuracy. Parameters ---------- logits : jax.numpy.ndarray Final layer activations. labels : jax.numpy.ndarray True labels. Returns ------- float Accuracy. """ preds = jnp.argmax(logits, axis=1)return (preds == labels).mean()
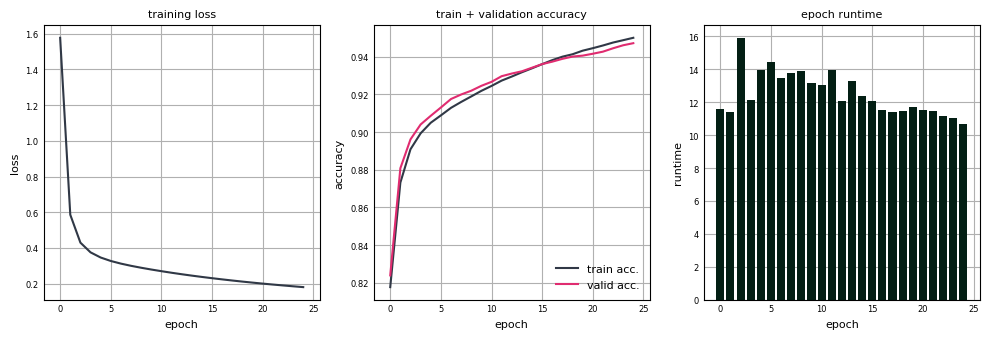
We have everything setup train the network. The training loop is provided in the next cell, where the network is trained for 25 epochs:
from time import perf_counter# Layer sizes.sizes = [784, 128, 10]# Number of epochs.n_epochs =25# Learning rate.lr =0.01# Store loss, accuracy and runtime.results = []# Initialize weights ands biases.params = initialize_weights(sizes, key=random.PRNGKey(516), scale=.02) for epoch inrange(n_epochs): start_time = perf_counter() losses = [] for X, y in train_batches:# Compute loss. params, loss = update(params, X, y, lr=lr) losses.append(loss.item()) epoch_time = perf_counter() - start_time avg_loss = np.mean(losses) train_acc = np.mean([accuracy(forward(params, X), y).item() for X, y in train_batches]) valid_acc = np.mean([accuracy(forward(params, X), y).item() for X, y in valid_batches]) results.append((epoch +1, avg_loss, train_acc, valid_acc, epoch_time))print(f"Epoch {epoch +1}/{n_epochs}: loss: {avg_loss:.4f}, train acc.: {train_acc:.3f}, valid acc.: {valid_acc:.3f}, time: {epoch_time:.2f} sec.")
Given the shape of the training and validation accuracy curves, it’s likely that the network still had room to improve, and with additional epochs would almost certainly have achieved even better performance.
JIT Compilation
On average, it took around 13 seconds for one full pass through the data using CPU. We can reduce the runtime drastically by just-in-time compiling the update function. Recall from the first installment of the series that Just-In-Time (JIT) compilation in JAX refers to the process of transforming a Python function into highly optimized, low-level code (usually XLA-compiled) that runs much faster. This can be accomplished using the @jit decorator. update now becomes:
from jax import jit@jitdef update(params, X, y, lr=.01):""" Update weights and biases using gradient descent. Parameters ---------- params : list of tuples List of tuples containing weights and biases for each layer. X : jax.numpy.ndarray Input data. y : jax.numpy.ndarray True labels. lr : float Learning rate. Returns ------- tuple Updated weights and biases. """# Compute loss and gradients. loss, grads = value_and_grad(cross_entropy_loss)(params, X, y)# Unpack parameters and gradients. (W1, b1), (W2, b2) = params (dW1, db1), (dW2, db2) = grads# Update weights and biases. W1_new = W1 - lr * dW1 b1_new = b1 - lr * db1 W2_new = W2 - lr * dW2 b2_new = b2 - lr * db2return [(W1_new, b1_new), (W2_new, b2_new)], loss
Let’s retrain the network and assess the impact JIT compilation has on per-epoch training time:
"""Same training loop as before, but now using JIT compilation."""from time import perf_counter# Layer sizes.sizes = [784, 128, 10]# Number of epochs.n_epochs =25# Learning rate.lr =0.01# Store loss, accuracy and runtime.results = []# Initialize weights ands biases.params = initialize_weights(sizes, key=random.PRNGKey(516), scale=.02) for epoch inrange(n_epochs): start_time = perf_counter() losses = [] for X, y in train_batches:# Compute loss. params, loss = update(params, X, y, lr=lr) losses.append(loss.item()) epoch_time = perf_counter() - start_time avg_loss = np.mean(losses) train_acc = np.mean([accuracy(forward(params, X), y).item() for X, y in train_batches]) valid_acc = np.mean([accuracy(forward(params, X), y).item() for X, y in valid_batches]) results.append((epoch +1, avg_loss, train_acc, valid_acc, epoch_time))print(f"Epoch {epoch +1}/{n_epochs}: loss: {avg_loss:.4f}, train acc.: {train_acc:.3f}, valid acc.: {valid_acc:.3f}, time: {epoch_time:.2f} sec.")
By simply adding the jit decorator to the update function, the average training time per epoch dropped from around 13 seconds to under a second, with no degradation of performance. Pretty remarkable!
Conclusion
JAX is a powerful tool for deep learning because it combines NumPy-like syntax with automatic differentiation, just-in-time (JIT) compilation for performance, and seamless GPU/TPU support, all while enabling functional programming patterns that make complex model transformations and optimization easier to express. In this series, we’ve only scratched the surface of what’s possible with JAX. For those eager to explore further, I recommend Deep Learning with JAX by Grigory Sapunov, which dives into more advanced topics and real-world applications of the framework.
I’m currently spending time getting familiar with Flax, a powerful, higher-level deep learning library that makes it easier to define, train, and manage models without sacrificing flexibility or performance (you can think of JAX as the engine and Flax as the framework that helps you build with that engine). It offers tools to define neural networks, handle parameter initialization and state management, and integrates nicely with JAX’s functional approach. It’s designed to make building and training deep learning models easier and more scalable without hiding the JAX underpinnings. More on Flax in a future post.