Understanding the Graph Convolutional Network Propogation Model
Walking through the forward pass described in the Kipf and Welling paper
Machine Learning
Python
Published
February 5, 2024
Convolutional Neural networks (CNNs) have been found to be very effective at tasks such as facial recognition, video analysis, anomaly detections and semantic parsing. An image can be considered a graph with a very regular structure (i.e., pixels are considered nodes, with edges connecting adjacent nodes). A natural idea is to extend convolutions to general graphs for tasks such as graph, node or edge classification. However, it is not immediately clear how one would go about extending the concept of convolutions in the context of CNNs to graphs.
In the Kipf and Welling paper, Semi-Supervised Classification with Graph Convolutional Networks, the authors propose a method to approximate the spectral graph convolution via truncated Chebyshev polynomials, resulting in an efficient and scalable method to train graph neural networks. In this post, we walkthrough the graph convolutional network (GCN) propagation model, which we also implement in pytorch geometric. Thomas Kipf’s original PyTorch implementation is available here.
Where: - \(\boldsymbol{n}\): number of nodes in graph
- \(\boldsymbol{c}\): length of feature vector for each node
- \(\boldsymbol{f}\): size of projection layer
- \(\boldsymbol{A}\): n-by-n adjacency matrix
- \(\boldsymbol{\tilde{A}}\): n-by-n adjacency matrix with added self-connections
- \(\boldsymbol{\tilde{D}}\): n-by-n degree matrix of \(\boldsymbol{\tilde{A}}\)
- \(\boldsymbol{H^{(l+1)}}\): n-by-c matrix of feature vectors for all nodes
- \(\boldsymbol{W^{(l)}}\): c-by-f linear projection layer
- \(\boldsymbol{\sigma}\): non-linearity, such as ReLU
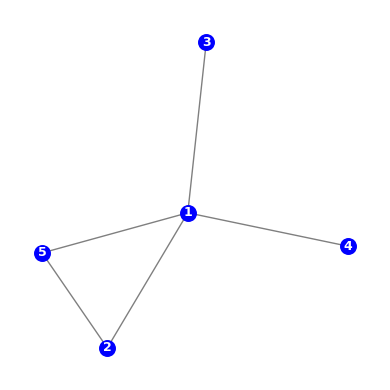
This becomes clear with an example. We create an undirected graph with 5 nodes:
The elements of the adjacency matrix indicate whether pairs of vertices are connected in the graph. For the graph shown above, the adjacency matrix is given by:
The first row indicates the nodes adjacent to node 1. Since node 1 is connected to all other nodes, all but the first cell are set to 1 (no self connections in \(A\)).
\(\tilde{A} = A + I\), where \(I\) is the length-n identity matrix. This has the effect of adding self-connections to each node. We have:
To get to \(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}}\), each element of \(\tilde{A}\) is divided by \(1 / \sqrt{d_{i} d_{j}}\) for entries in \(\tilde{D}\). This normalization ensures the largest eigenvalue = 1, and addresses the issue of exploding/vanishing gradients during training:
Note that during training, \(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}}\) is only computed once since the values will not change.
Each node has an associated feature vector of length \(c\). \(H^{(l)}\) represents stacked feature vectors for all nodes, resulting in a matrix of dimension n-by-c. \(H^{(0)} = X\), the original features.
\(W^{(l)}\) is the linear projection layer, which reduces the representation of each node from length c to length f. If we assume f = 64, \(H^{(l+1)}\) becomes:
The authors begin with an expression to perform spectral convolutions on graphs:
\[
g_{\theta} \star x = U g_{\theta} U^{T} x,
\]
where \(U\) is the matrix of eigenvectors of the normalized Laplacian \(L = I_{n} - D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\), and \(U^{T}x\) represents the graph Fourier transform of \(x\). However, this as expensive operation, since the spectral decomposition is \(\mathcal{O}(n^{3})\) in practice. In addition, it isn’t immediately clear how one would go about incorporating this operation within the context of forward/back-propagation.
Citing a paper by Hammond et. al, they propose an approximation to \(g_{\theta} \star x\) via a truncated expansion in terms of Chebyshev polynomials \(T_{k}(x)\) up to \(K^{th}\) order:
\[
g_{\theta} \star x \approx \sum_{k=0}^{K} \theta^{'}_{k} T_{k}(\tilde{L})x \hspace{.75em}(*),
\]
where \(\tilde{L} = \frac{2}{\lambda_{\mathrm{max}}}L - I_{N}\) and \(\theta^{'}\) is a vector of Chebyshev coefficients. Note that for the Chebyshev polynomial expansion, \(T_{0}(x) = 1\), \(T_{1}(x) = x\) and all other terms are recursively defined as \(T_{k}(x) = 2xT_{k-1}(x) - T_{k-2}(x)\).
By leveraging \({(*)}\) to approximate graph convolutions, the runtime complexity becomes linear in terms of the number of edges (\(\mathcal{O}(|\mathcal{E}|)\) instead of cubic in the number of nodes as is the case for the full spectral graph convolution.
From this point, the authors make three simplifications/assumptions which result in the propagation model introduced earlier:
The first two simplifications are \(K=1\) and \(\lambda_{\mathrm{max}} = 2\). Expanding \(({*})\) with \(K=1\) and \(\lambda_{\mathrm{max}} = 2\) results in:
The third simplification sets \(\theta = \theta^{'}_{0} = -\theta^{'}_{1}\). This constrains the number of parameters to address overfitting and to minimize the number of multiplications per layer. Doing so results in:
To address the issue of exploding/vanishing gradients during training they apply a renormalization trick, essentially swapping \(A\) and \(D\) with \(\tilde{A}\) and \(\tilde{D}\). This ensures eigenvalues are the the range [-1, 1]. We can show this is the case for our example using the adjacency matrix associated with our 5 node graph:
import numpy as npimport networkx as nxnp.set_printoptions(suppress=True, precision=5)G = nx.Graph()edges = [(1, 2), (1, 3), (1, 4), (1, 5), (2, 5)]G.add_edges_from(edges)A = nx.adjacency_matrix(G).todense()I = np.identity(5)D = np.diag(np.sum(A, axis=1))# Check range of eigenvalues without renormalization.Dp = np.linalg.inv(np.power(D, .5))evals0, _ = np.linalg.eig(I + Dp @ A @ Dp)# Check range of eigenvalues after renormalization trick. Atilde = A + IDtilde = np.diag(np.sum(Atilde, axis=1))Dtildep = np.linalg.inv(np.power(Dtilde, .5))evals1, _ = np.linalg.eig(Dtildep @ Atilde @ Dtildep)print(f"\neigenvalues without renormalization: {evals0}")print(f"eigenvalues with renormalization : {evals1}")
eigenvalues without renormalization: [0.19098 2. 1.30902 0.5 1. ]
eigenvalues with renormalization : [-0.22526 1. 0.59192 0.5 0. ]
By replacing \(\big(I_{N} + D^{-\frac{1}{2}}AD^{-\frac{1}{2}} \big)\) with \(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}}\), we end up with:
\[
Z = \tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}X\Theta,
\]
where \(\Theta\) is a c-by-f matrix of filter parameters and \(Z\) is the n-by-f convolved signal matrix.
The final propagation model has nothing to do with the spectral decomposition: No eigenvectors/eigenvalues are actually computed. The approach was motivated by spectral convolutions on graphs, but is not a spectral method itself.
PyTorch Geometric GCN Implementation
In what follows, we demonstrate how to set up a 2-layer GCN for node classification using PyTorch Geometric and the Cora citation network.
import randomimport matplotlib.pyplot as pltimport networkx as nximport numpy as npimport pandas as pdimport torchfrom torch_geometric.datasets import Planetoidimport torch_geometric.transforms as Tfrom torch_geometric.utils import to_networkxdevice = torch.device("cuda:0"if torch.cuda.is_available() else"cpu")dataset = Planetoid(root='/tmp/Cora', name='Cora')split = T.RandomNodeSplit(num_val=0.15, num_test=0.10)graph = split(dataset[0])
Distribution of classes in Cora
The Cora dataset is a citation network, where each node represents a paper belonging to one of the following 7 classes. Our goal is to predict the labels assigned to each node in the network:
Next we implement GCN using PyTorch Geometric. The original PyTorch implementation is available here.
import torch.nn as nnfrom torch_geometric.nn import GCNConvimport torch.nn.functional as Fclass GCN(nn.Module):def__init__(self, num_features, num_classes):super().__init__()self.conv1 = GCNConv(num_features, 64)self.conv2 = GCNConv(64, num_classes)def forward(self, data): x, edge_index = data.x, data.edge_index x =self.conv1(x, edge_index) x = F.relu(x) output =self.conv2(x, edge_index)return(output)def train_classifier(model, graph, optimizer, criterion, n_epochs=100):""" Training loop. """ tm, vm = graph.train_mask, graph.val_maskfor epoch inrange(n_epochs): model.train() optimizer.zero_grad() output = model(graph) loss = criterion(output[tm], graph.y[tm]) loss.backward() optimizer.step()# Validate. model.eval() pred = model(graph).argmax(dim=1) correct = (pred[vm] == graph.y[vm]).sum() acc = correct / vm.sum()if epoch %10==0:print(f"Epoch {epoch}: train loss={loss:.3f}, val. acc={acc:.3f}.")return(model)
Training our network:
# Capture activations from last hidden layer to re-create plot# from paper.activations = {}def get_activation(name):def hook(gcn, input, output): activations[name] = output.detach()return(hook)# Put graph on GPU if available.graph = graph.to(device)gcn = GCN(num_features=1433, num_classes=7).to(device)gcn.conv2.register_forward_hook(get_activation("conv2"))optimizer = torch.optim.Adam(gcn.parameters(), lr=0.01, weight_decay=1e-4)criterion = nn.CrossEntropyLoss()gcn = train_classifier(gcn, graph, optimizer, criterion)# Compute test accuracy.gcn.eval()pred = gcn(graph).argmax(dim=1)correct = (pred[graph.test_mask] == graph.y[graph.test_mask]).sum()test_acc = correct / graph.test_mask.sum()print(f"\nTest accuracy: {test_acc:.3f}\n")
Epoch 0: train loss=1.932, val. acc=0.303.
Epoch 10: train loss=0.377, val. acc=0.862.
Epoch 20: train loss=0.181, val. acc=0.867.
Epoch 30: train loss=0.119, val. acc=0.857.
Epoch 40: train loss=0.088, val. acc=0.852.
Epoch 50: train loss=0.069, val. acc=0.845.
Epoch 60: train loss=0.058, val. acc=0.847.
Epoch 70: train loss=0.050, val. acc=0.850.
Epoch 80: train loss=0.044, val. acc=0.855.
Epoch 90: train loss=0.040, val. acc=0.855.
Test accuracy: 0.893
Display hidden layer activations with t-SNE
Finally, we can display a lower dimensional representation of the final hidden layer node embeddings using t-SNE. The resulting plot looks similar to figure 1b from the original paper, but experimenting with the t-SNE perplexity parameter will probably get you even closer: