Principal Component Analysis (PCA) is a statistical technique used in the field of data analysis and machine learning for dimensionality reduction while preserving as much of the data’s variation as possible. It’s particularly useful when dealing with high-dimensional data, helping to simplify the data without losing the underlying structure. These components are orthogonal (meaning they are statistically independent of one another), and are ordered so that the first few retain most of the variation present in all of the original variables. There are a number of uses for PCA, including:
Visualization: By reducing data to two or three principal components, PCA allows for the visualization of complex data in a 2D or 3D space.
Noise Reduction: By eliminating components with low variance and retaining those with high variance, PCA can help in reducing noise in the dataset.
Feature Extraction and Data Compression: PCA can help in extracting the most important features from the data, which can then be used for further analysis or machine learning modeling. It also helps in compressing the data by reducing the number of dimensions without losing significant information.
Improving Model Performance: By reducing the dimensionality, PCA can lead to simpler models that are less prone to overfitting when training on datasets with a high number of features.
There are some limitations to PCA, specifically:
Linear Assumptions: PCA assumes that the principal components are a linear combination of the original features, which may not always capture the structure of the data well, especially if the underlying relationships are non-linear.
Sensitivity to Scaling: Since PCA is affected by the scale of the features, different results can be obtained if the scaling of the data changes.
Data Interpretation: Interpretability of the principal components can be difficult since they are combinations of all original features.
The spread of a dataset can be expressed in orthonormal vectors – the principal directions of the dataset. Orthonormal means that the vectors are orthogonal to each other (i.e. they have an angle of 90 degrees) and are of size 1. By sorting these vectors in order of importance (by looking at their relative contribution to the spread of the data as a whole), we can find the dimensions of the data which explain the most variance. We can then reduce the number of dimensions to the most important ones only. Finally, we can project our dataset onto these new dimensions, called the principal components, performing dimensionality reduction without losing much of the information present in the dataset.
In what follows, PCA is demonstrated from scratch using Numpy and the results compared with scikit-learn to show they are identical up to a sign.
Extracting the first k Principal Components
We start by 0-centering the data, then compute the Singular Value Decomposition (SVD) of the data matrix \(A\), where rows of \(A\) are assumed to be samples and columns the features. For any \(m \times n\) data matrix \(A\), the SVD factors \(A = U \Sigma V^{T}\) where:
\(U\) = an \(m \times m\) orthogonal matrix whose columns are the left singular vectors of \(A\).
\(V\) = an \(n \times n\) orthogonal matrix whose columns are the right singular vectors of \(A\).
\(\Sigma\) = is an \(m \times n\) diagonal matrix containing the singular values of \(A\) in descending order along the diagonal. These values are non-negative and are the square roots of the eigenvalues of both \(A^{T}A\) and \(AA^{T}\).
The remaining steps are shown in code below:
import numpy as npnp.set_printoptions(suppress=True, precision=8, linewidth=1000)rng = np.random.default_rng(516)# Specify the number of principal components to retain.k =5# Create random matrix with 100 samples and 50 features.Xinit = rng.normal(loc=100, scale=12.5, size=(100, 50))# 0-center columns in Xinit. Each column will now have mean 0. X = Xinit - Xinit.mean(axis=0)# Compute SVD of 0-centered data matrix X.# U : (100, 100) Columns represent left singular vectors.# VT: (50, 50) Rows represent right singular vectors.# S : (50,) Represents singular values of X. U, S, VT = np.linalg.svd(X)# Apply dimensionality reduction (retain first k principal components).# Xpca1 will have shape 100 x k. Xpca1 = X @ VT[:k].Tprint(f"Xpca1.shape: {Xpca1.shape}")
Xpca1.shape: (100, 5)
This returns the top-5 principal components from the 0-centered data matrix \(X\). This transformation can also be carried out in scikit-learn as follows:
from sklearn.decomposition import PCA# Call pca.fit on 0-centered data matrix.pca = PCA(n_components=k)pca.fit(X)Xpca2 = pca.transform(X)print(f"Xpca2.shape: {Xpca2.shape}")
Xpca2.shape: (100, 5)
The first few rows of Xpca1 and Xpca2 can be compared. Notice that they are identical up to a sign:
The reason for the discrepancy is due to the fact that each singular vector is only uniquely determined up to sign, indeed in more generality it is only defined up to complex sign (i.e. up to multiplication by a complex number of modulus 1). For a deeper mathematical explanation of this, check out this link.
Assessing Reconstruction Error
Once the principal components of a data matrix have been identified, we can get an idea of how well using k components approximates the original matrix. If we use all principal components, we should be able to recreate the data exactly. The objective is to identify some reduced number of components that captures enough variance in the original data while also eliminating redundant components. Thus, minimizing the reconstruction error is equivalent to maximizing the variance of the projected data. Using the pca.inverse_transform method, we can project our k-component matrix back into signal space (100 x 50 for our example), and compute the reconstruction error (the average difference between the original data matrix and our projected matrix):
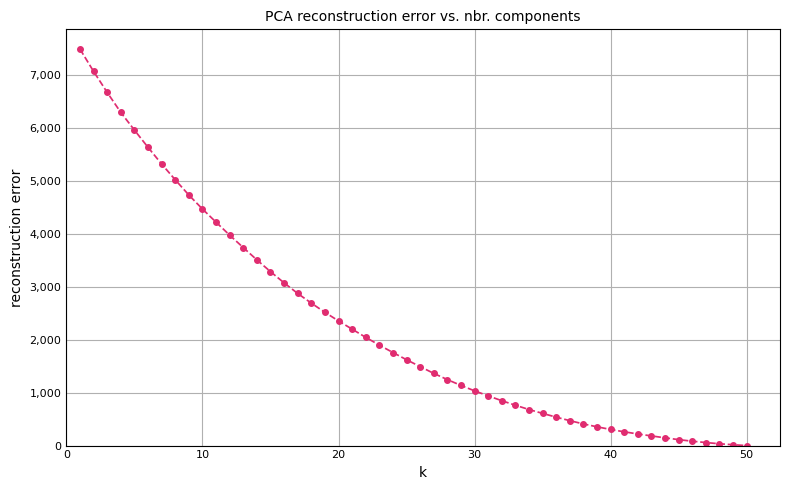
We can then plot the reconstruction error as a function of the number of retained components:
# Plot reconstruction error as a function of k-components.import matplotlib as mplimport matplotlib.pyplot as pltxx, yy =zip(*reconstruction_error)fig, ax = plt.subplots(figsize=(8, 5), tight_layout=True)ax.set_title("PCA reconstruction error vs. nbr. components", fontsize=10)ax.plot(xx, yy, color="#E02C70", linestyle="--", linewidth=1.25, markersize=4, marker="o")ax.set_xlabel("k", fontsize=10)ax.set_ylabel("reconstruction error", fontsize=10)ax.set_ylim(bottom=0)ax.set_xlim(left=0)ax.tick_params(axis="x", which="major", direction="in", labelsize=8)ax.tick_params(axis="y", which="major", direction="in", labelsize=8)ax.get_yaxis().set_major_formatter(mpl.ticker.FuncFormatter(lambda x, p: format(int(x), ',')))ax.xaxis.set_ticks_position("none")ax.yaxis.set_ticks_position("none")ax.grid(True)plt.show()
A few things to note about the reconstruction error curve:
We started with random normal data, so there was no information in the original features to begin with. When applied to real-world data, you will typically see a sharp decrease in reconstruction error after some small set of k-components.
Notice when k = 50, the reconstruction error drops to 0. With 50 components, we are able to reproduce the original data exactly.
PCA Loadings
PCA loadings are the coefficients of the linear combination of the original variables from which the principal components are constructed. From scikit-learn’s pca output, we simply need to access the pca.components_ attribute, the rows of which contain the eigenvectors associated with the first k principal components:
The interpretation of this output is that the coefficient for column index 27 is .367146, and is the largest contributor to the score for each observation when applied to the original data.
We can show how the loadings are used to compute the PCA scores for the first sample in the dataset. Let’s find the first principal component of our original 0-centered data matrix \(X\):
The value 1.0024489 is obtained by computing the dot product of the first principal component loading with the first row in \(X\):
np.dot(pca.components_.T.ravel(), X[0, :])
1.0024488966036473
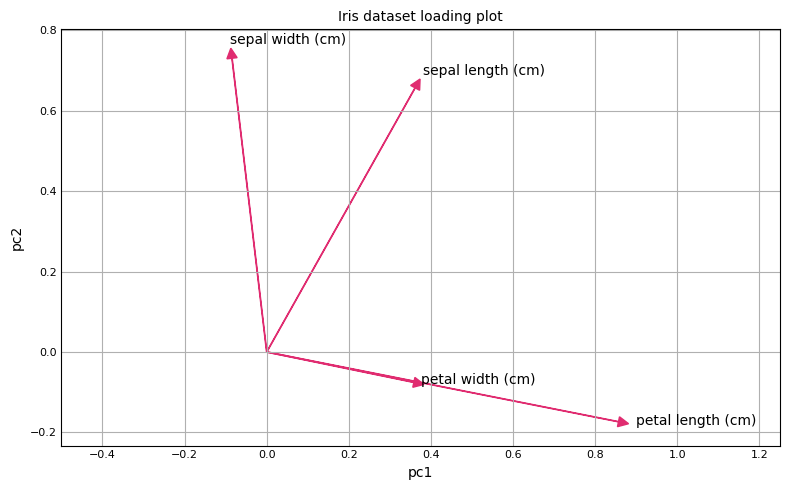
Loading Plot
PCA loading plots are visual tools used to interpret the results of PCA by showing how much each variable contributes to the principal components. These plots help in understanding the underlying structure of the data and in identifying which variables are most important in driving the differences between observations. They provide insight into the relationship between the variables and the principal components. In the next cell, we show how to create a loading plot for the iris dataset in scikit-learn.
In the direction of the first principal component, petal length has the largest effect, whereas sepal length is the dominant feature in the direction of the second principal component.
Using PCA in ML Pipeline
How might we use PCA in a typical machine learning workflow?
from sklearn.decomposition import PCApca = PCA(n_components=5).fit(Xtrain)Xtrain_pca = pca.transform(Xtrain)Xtest_pca = pca.transform(Xtest)
Xtrain and Xtest would then be used as the train and test sets as in any other machine learning setup. Note that we call fit on the training set, then only transform on the test set. This prevents information from the test set leaking into the training data. Xtrain_pca and Xtest_pca will have the same number of rows as Xtrain and Xtest, but will only have 5 features, which will be less than or equal to the number of features in Xtrain and Xtest.